
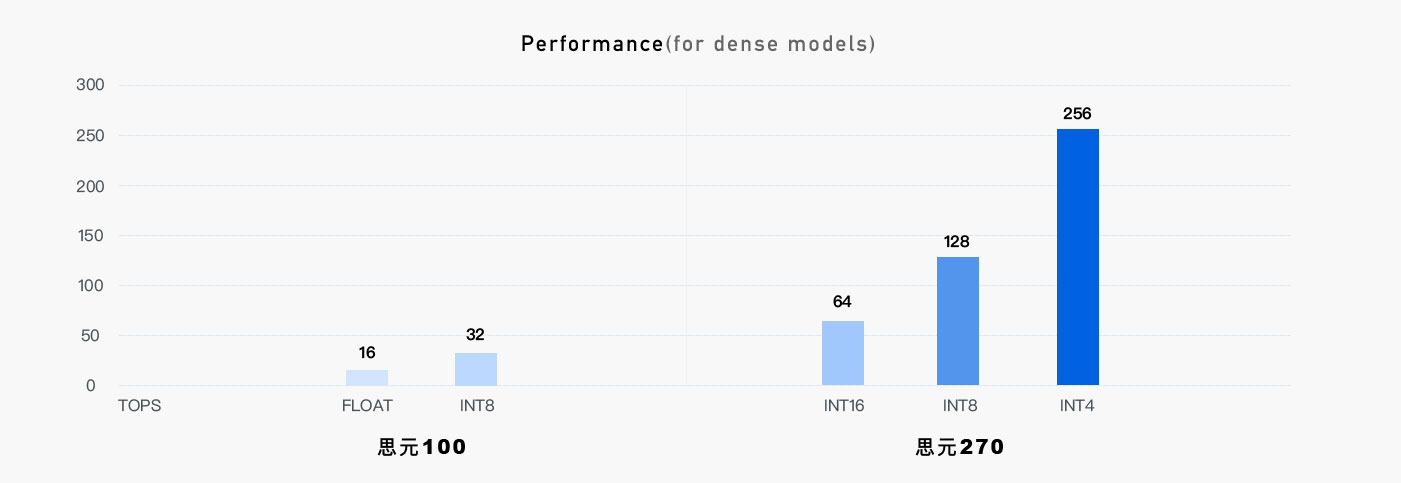
思元270集成了寒武纪在处理器架构领域的一系列创新性技术,处理非稀疏深度学习模型的理论峰值性能提升至上一代思元100的4倍,达到128TOPS(INT8);同时兼容INT4和INT16运算,理论峰值分别达到256TOPS和64TOPS;支持浮点运算和混合精度运算。
思元270采用寒武纪MLUv02架构,可支持视觉、语音、自然语言处理以及传统机器学习等多样化的人工智能应用,更为视觉应用集成了充裕的视频和图像编解码硬件单元。

MLUv02架构不是简单的从上一代升级而来,新架构基于片上网络(NOC)构建,保证思元270芯片内多达16 个张量核心的并行效率。基于硬件的片内数据压缩,提升缓存有效容量和带宽。

新架构在采用INT8精度进行AI推理计算时,非稀疏网络性能比第一代加速卡提升高达4倍,可为系统提供40倍于CPU的超高能效比。
思元270芯片支持多类神经网络,寒武纪NeuWare软件栈可以轻松部署推理环境。BANG Lang.编程环境可对计算资源做直接定制,满足多样化AI定制要求,专业而不专用。

思元270芯片采用寒武纪MLUv02架构,搭载EOTS(Edge outlet thermal system)主动散热技术的MLU270-F4,可轻松胜任非数据中心部署环境。可支持最高150W散热功率,在面向繁重AI推理任务时,思元270的推理性能可充分发挥。思元270处理非稀疏深度学习模型的理论峰值性能提升至上一代思元100的4倍,可广泛支持视觉、语音、自然语言处理以及传统机器学习等高度多样化的人工智能应用,为您的个人电脑和工作站提供专业的AI加速能力。
面向非数据中心AI推理
| 思元270-F4 产品规格 | ||
|---|---|---|
| 产品性能 |
芯片型号 INT8理论峰值/TOPS INT4理论峰值/TOPS INT16理论峰值/TOPS |
思元270(MLUv02 架构) 128 256 64 |
| 计算精度支持 | 低精度、混合精度 | INT16,INT8,INT4,FP32,FP16 |
| 内存规格 | 内存容量 内存位宽 内存带宽 |
16GB DDR4,ECC 256-bit 102GB/s |
| 接口 | PCIe接口 | x16 PCIe Gen.3 |
| 功耗 | 最大热设计功耗 (TDP) 最大整板功耗 (TBP) 散热设计 |
150w 160w |
| 形态 | 全高,全长,双槽位 | |
| 尺寸 | 267mm x 111.15mm | |
| 重量 | 874g | |



